Save your entities 20× faster with EF Extensions
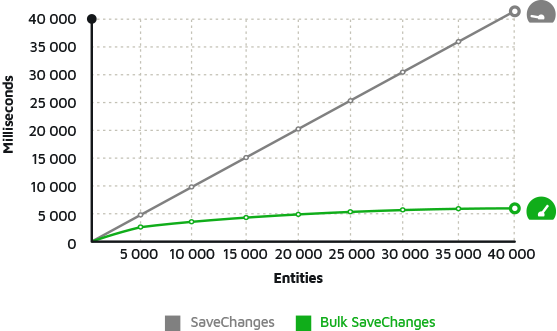
SaveChanges vs BulkSaveChanges
Our Knowledge Base was created to give an alternative to Stack Overflow to find answers with a different view. However, due to search engines that now need to fight spam and generated content more than ever, our KB was severely hurting our ranking, and we had to shut it down on 2023-01-17.
Take me back to Entity Framework 6 Home